24小(xiǎo)时联系電(diàn)话:18217114652、13661815404
中文(wén)
路板设计")

- 您当前的位置:
- 首页>
- 電(diàn)子资讯>
- 技术专题>
- 单片机开发功能(néng)安全中...
技术专题
单片机开发功能(néng)安全中的编译器
在各个领域,功能(néng)安全领域对开发人员提出了新(xīn)要求。功能(néng)上安全的代码必须包括防御性代码,以防御各种原因引起的意外事件。例如,由于编码错误或宇宙射線(xiàn)事件而导致的内存损坏可(kě)能(néng)导致执行根据代码逻辑“不可(kě)能(néng)”的代码路径。高级语言,特别是C和C ++,包含数量众多(duō)的功能(néng),这些功能(néng)的行為(wèi)不是代码所遵循的语言规范所规定的。这种不确定的行為(wèi)可(kě)能(néng)导致意外的结果和潜在的灾难性后果,而这在功能(néng)安全的应用(yòng)程序中是无法接受的。出于这些原因,标准要求应用(yòng)防御性编码,可(kě)测试的编码,有(yǒu)可(kě)能(néng)整理(lǐ)足够的编码覆盖率,
代码还必须实现高级别的代码覆盖率,在某些领域(尤其是汽車(chē)领域),设计通常需要复杂的外部诊断,校准和开发工具。出现的问题是,防御性编码和外部数据访问等实践并不属于编译器认可(kě)的领域。例如,C和C ++都没有(yǒu)為(wèi)内存损坏留出任何余地,因此,除非在没有(yǒu)这种损坏的情况下可(kě)以访问旨在防止内存损坏的代码,否则在对代码进行优化时可(kě)以将其忽略。因此,如果不“优化”防御性代码,则必须在语法和语义上都可(kě)以实现。
未定义行為(wèi)的实例也会引起意外。很(hěn)容易建议应避免使用(yòng)它们,但通常很(hěn)难识别它们。如果存在它们,就不能(néng)保证已编译的可(kě)执行代码的行為(wèi)将符合开发人员的意图。对调试工具使用(yòng)的数据的“后门”访问代表了该语言不允许的另一种情况,因此可(kě)能(néng)会带来意想不到的后果。
编译器优化可(kě)能(néng)对所有(yǒu)这些领域产生重大影响,因為(wèi)它们都不属于编译器供应商(shāng)的职责范围。优化可(kě)能(néng)会导致在与“不可(kě)行”相关联时,即在存在于无法通过任何可(kě)能(néng)的输入值进行测试和验证的路径上存在的情况下,显然消除了防御性代码。更令人震惊的是,在构建系统可(kě)执行文(wén)件时,很(hěn)可(kě)能(néng)会消除在单元测试期间显示的防御代码。仅仅因為(wèi)在单元测试期间已经实现了防御性代码的覆盖范围,因此并不能(néng)保证其已存在于完整的系统中。
在功能(néng)安全这个陌生的领域,编译器可(kě)能(néng)超出了其要素。这就是為(wèi)什么目标代码验证(OCV)代表了对任何与故障相关的后果都有(yǒu)严重后果的系统的最佳实践,甚至对于只有(yǒu)最佳实践就足够好的任何系统都代表了最佳实践。
编译前后
功能(néng)安全性,安全性和编码标准(例如IEC 61508,ISO 26262,IEC 62304,MISRA C和C ++)提倡的验证和确认做法非常强调显示在基于需求的测试中使用(yòng)了多(duō)少应用(yòng)程序源代码。
经验向我们表明,如果已证明代码可(kě)以正确执行,则现场失败的可(kě)能(néng)性会大大降低。但是,由于这种值得称赞的努力的重点是高级源代码(无论使用(yòng)哪种语言),所以这种方法使编译器具有(yǒu)创建目标代码的能(néng)力,这些目标代码可(kě)以准确地再现开发人员的能(néng)力,这使人们深信不疑预期的。在最关键的应用(yòng)程序中,该隐含假设无法成立。
不可(kě)避免的是,目标代码的控制和数据流不会完全是源代码的镜像,因此证明所有(yǒu)源代码路径都可(kě)以可(kě)靠地行使并不能(néng)证明目标代码是同一件事。 。鉴于目标代码和汇编器之间存在1:1的关系,因此可(kě)以比较源代码和汇编代码。考虑一下图1所示的示例,其中右边的汇编代码是从左边的源代码生成的(使用(yòng)禁用(yòng)了优化的TI编译器)。

图1:右边的汇编代码是从左边的源代码生成的,显示了源代码和汇编代码之间的明显对比
如下所述,当编译此源代码时,生成的汇编代码的流程图与源代码的流程图完全不同,因為(wèi)C或C ++编译器遵循的规则允许它们以自己喜欢的任何方式修改代码,前提是二进制表现為(wèi)“好像是一样的。”
在大多(duō)数情况下,该原则是完全可(kě)以接受的-但存在异常情况。编译器优化基本上是数學(xué)上的变换,可(kě)应用(yòng)于代码的内部表示。如果假设不成立,这些转换就会“出错”-例如,在代码库包含未定义行為(wèi)的实例的情况下,这种情况经常发生。
只有(yǒu)航空航天业中使用(yòng)的DO-178C才将重点放在开发人员意图与可(kě)执行行為(wèi)之间潜在的危险不一致的可(kě)能(néng)性上,即使如此,仍不难找到具有(yǒu)明显潜能(néng)的解决方法的倡导者,以免发现那些不一致之处。但是,可(kě)以原谅此类方法,但事实是,源代码和目标代码之间的差异可(kě)能(néng)在任何关键应用(yòng)程序中造成毁灭性后果。
开发人员意图与可(kě)执行行為(wèi)
尽管源代码流和目标代码流之间存在明显差异,但它们并不是主要问题。编译器通常是高度可(kě)靠的应用(yòng)程序,尽管可(kě)能(néng)会像其他(tā)任何软件一样存在错误,但编译器的实现通常会满足其设计要求。问题在于这些设计要求并不总是反映功能(néng)安全系统的需求。
简而言之,可(kě)以假定编译器在功能(néng)上符合其创建者的目标。但这可(kě)能(néng)并不完全是期望或期望的结果,如下面的图2所示,其中包括一个使用(yòng)CLANG编译器进行编译的示例。

图2显示了使用(yòng)CLANG编译器进行的编译
显然,在汇编代码中并未表达对“错误”功能(néng)的防御性呼吁。
仅在初始化“ state”对象时以及在“ S0”和“ S1”情况下修改“ state”对象,因此编译器可(kě)以推断出赋予“ state”的唯一值是“ S0”和“ S1”。编译器得出结论,不需要“默认值”,因為(wèi)假设没有(yǒu)损坏,“状态”将永遠(yuǎn)不包含任何其他(tā)值-实际上,编译器所做的正是这一假设。
编译器还决定,由于实际对象(13和23)的值未在数字上下文(wén)中使用(yòng),因此它将仅使用(yòng)0和1的值在状态之间切换,然后使用(yòng)异或“或”更新(xīn)状态值。二进制文(wén)件遵循“好像”义務(wù),并且代码快速紧凑。在其职权范围内,编译器做得很(hěn)好。
此行為(wèi)对使用(yòng)链接器内存映射文(wén)件间接访问对象的“校准”工具以及通过调试器直接访问内存有(yǒu)影响。同样,这些考虑因素也不属于编译器的职责范围,因此在优化和/或代码生成期间不会考虑。
现在假设代码保持不变,但是在呈现给编译器的代码中其上下文(wén)发生了微小(xiǎo)的变化,如图3所示。

图3:代码保持不变,但是提供给编译器的代码中的上下文(wén)略有(yǒu)变化
现在有(yǒu)一个附加函数,该函数以整数形式返回状态变量的值。这次,绝对值13和23在提交给编译器的代码中很(hěn)重要。即使这样,这些值也不会在更新(xīn)函数中进行操作(保持不变),并且仅在新(xīn)的“ f”函数中可(kě)见。
简而言之,编译器继续(正确地)对应该使用(yòng)13和23的值进行价值判断,并且绝不会将它们应用(yòng)于可(kě)能(néng)的所有(yǒu)情况。
如果更改了新(xīn)功能(néng)以返回指向我们状态变量的指针,则汇编代码将发生重大变化。由于现在存在通过指针进行别名访问的可(kě)能(néng)性,因此编译器无法再推断出状态对象正在发生的情况。如下图4所示,它不能(néng)得出13和23的值不重要的结论,因此现在可(kě)以在汇编器中明确表示它们。

图4:如果将新(xīn)函数更改為(wèi)返回指向我们的状态变量的指针,则汇编代码将发生重大变化。它不能(néng)得出结论13和23的值并不重要,因此它们现在已在汇编程序中明确表示
对源代码单元测试的影响
现在,在虚构的单元测试工具的上下文(wén)中考虑示例。由于需要一种工具来访问被测代码,因此会操纵状态变量的值,因此默认值不会“被优化”。这种方法在没有(yǒu)与源代码其余部分(fēn)相关的上下文(wén)并且需要使所有(yǒu)内容都可(kě)访问的测试工具中是完全合理(lǐ)的,但是,其副作用(yòng)是,它可(kě)以掩盖编译器对防御性代码的合法遗漏。
编译器认识到已通过指针将任意值写入状态变量,并且不能(néng)再次得出13和23的值不重要的结论。因此,它们现在在汇编器中明确表示。在这种情况下,不能(néng)得出结论:S0和S1代表状态变量的唯一可(kě)能(néng)值,这意味着默认路径可(kě)能(néng)可(kě)行。如图5所示,状态变量的操作达到了目的,并且在汇编器中现在可(kě)以明显看到对错误函数的调用(yòng)。

图5:状态变量的操作已达到其目的,并且错误函数的调用(yòng)现在在汇编程序中显而易见
但是,这种操作不会出现在产品内随附的代码中,因此对error()的调用(yòng)实际上不在整个系统中。
目标代码验证的重要性
為(wèi)了说明目标代码验证如何帮助解决这个难题,请再次考虑第一个示例代码片段,如图6所示:

图6:这说明了目标代码验证如何帮助解决错误提示在整个系统中的作用(yòng)
通过一次调用(yòng),可(kě)以证明此C代码实现了100%的源代码覆盖率,因此:
f_while4(0,3);
可(kě)以将代码重新(xīn)格式化為(wèi)每行单个操作,并在流程图上表示為(wèi)“基本块”节点的集合,每个节点都是一系列直線(xiàn)代码。基本块之间的关系在图7中使用(yòng)节点之间的有(yǒu)向边表示。

图7:使用(yòng)节点之间的有(yǒu)向边显示基本块之间的关系
编译代码后,结果如下所示(图8)。流程图的蓝色元素表示调用(yòng)f_while4(0,3)尚未执行的代码。
通过利用(yòng)目标代码与汇编代码之间的一对一关系,此机制可(kě)以揭示目标代码的哪些部分(fēn)未被执行,从而促使测试人员设计其他(tā)测试并实现完整的汇编代码覆盖范围,从而实现目标代码验证。
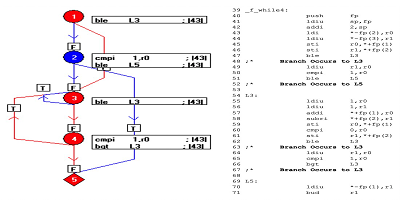
图8:显示了编译代码后的结果。流程图的蓝色元素表示调用(yòng)f_while4(0,3)尚未执行的代码
显然,目标代码验证无权阻止编译器遵循其设计规则,并无意中绕开了开发人员的最佳意图。但这确实可(kě)以并且确实会引起任何此类失配,引起粗心的人的注意。
现在,在前面的“错误提示”示例的上下文(wén)中考虑该原理(lǐ)。当然,完整系统中的源代码将与在单元测试级别上证明的源代码相同,因此,将其进行比较不会发现任何问题。但是,将目标代码验证应用(yòng)于完整的系统对于确保基本行為(wèi)按照开发人员的意图进行表达将具有(yǒu)极大的价值。